Flash Attention: Triton 实现
Triton 实现
这部分我们详解 Triton 官方提供的 Flash Attention v2 实现,再加一些实际的性能测试。
性能测试
先上性能表现。我自己做了个 benchmark,对比了该实现与 naive attention 的性能表现。Naive Attention 的代码:
def pytorch_attention(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, causal: bool, sm_scale: float) -> torch.Tensor:
scores = torch.matmul(q, k.transpose(-1, -2)) * sm_scale
if causal:
seq_len = q.shape[-2]
causal_mask = torch.triu(
torch.ones((seq_len, seq_len), device=q.device, dtype=torch.bool),
diagonal=1,
)
scores = scores.masked_fill(causal_mask, float("-inf"))
probs = torch.softmax(scores.float(), dim=-1).to(dtype=q.dtype)
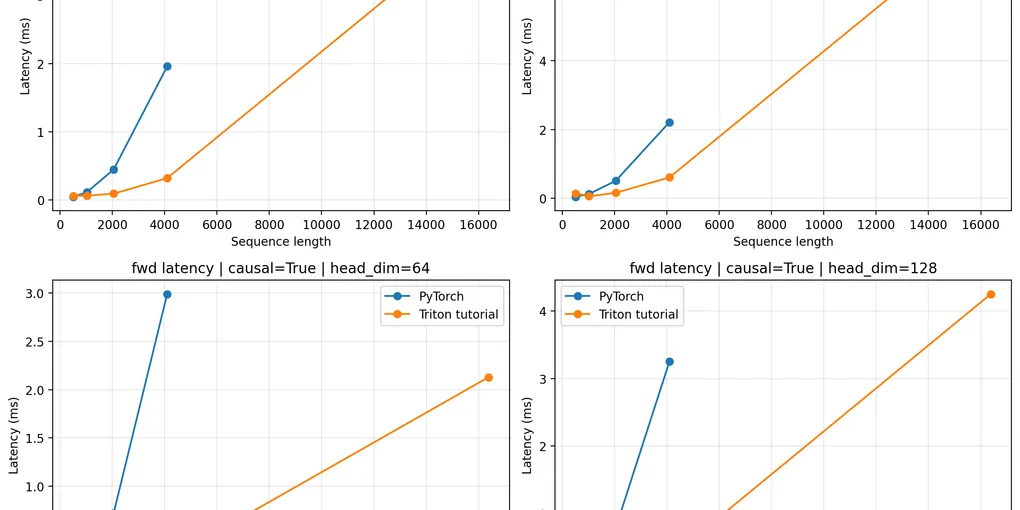
return torch.matmul(probs, v)性能测试结果:
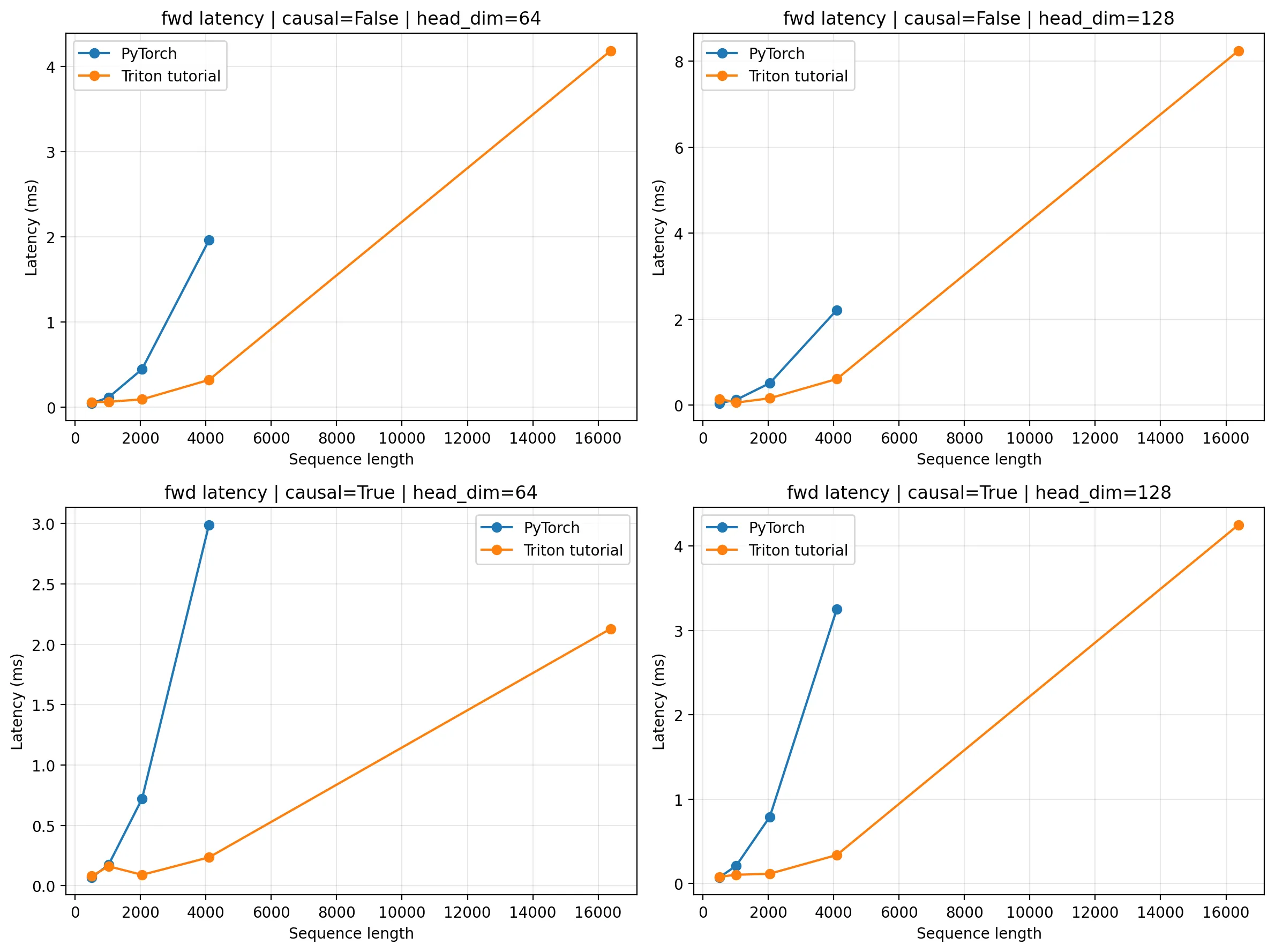
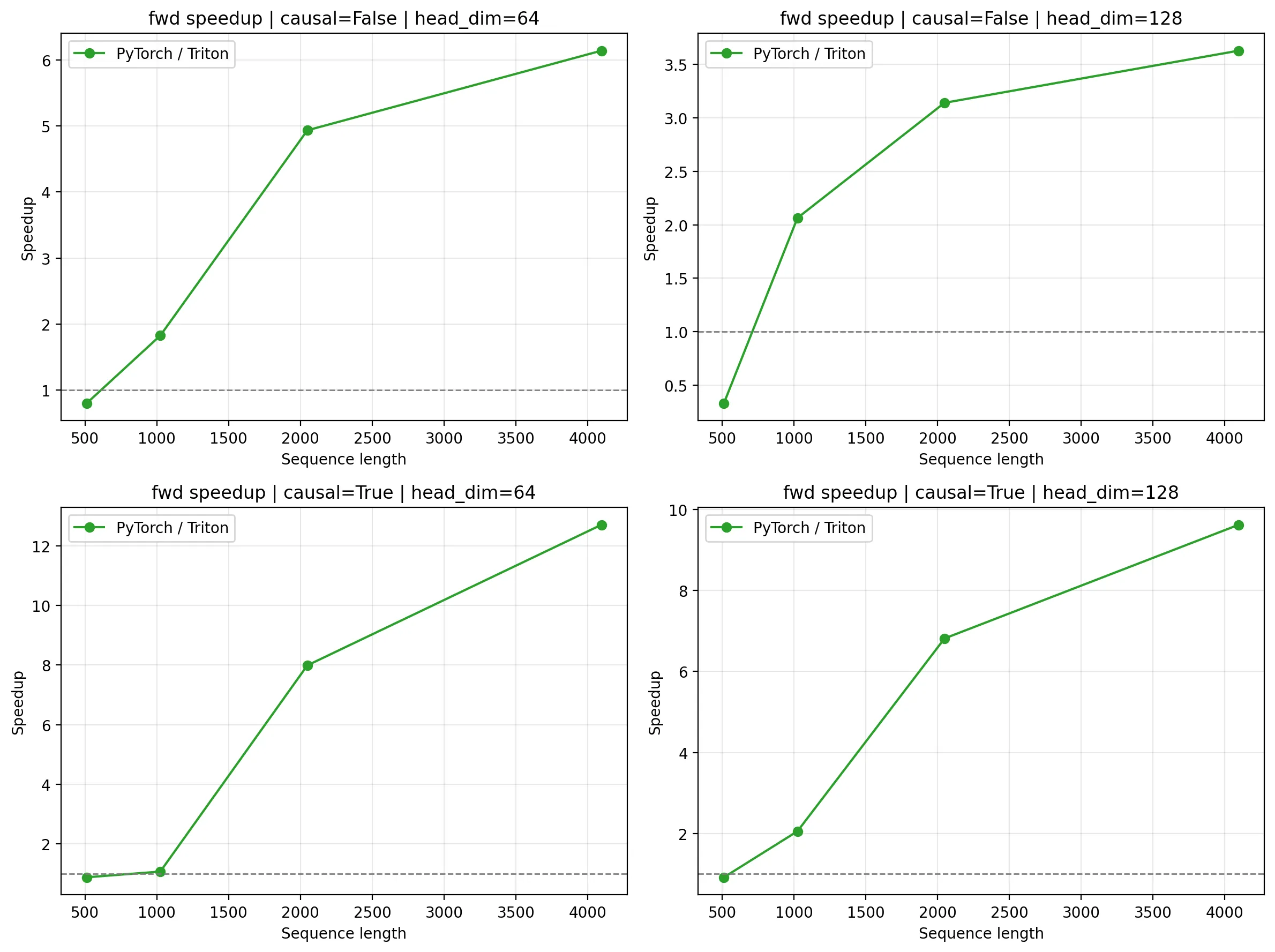
我们注意到 PyTorch 的 sequence length 范围要更小,这是因为显存爆炸了没办法跑。可见无论是性能还是显存占用,flash attention 表现都要更好。
代码详解
Grid 与并行策略
# fa_tutorial.py L550-L551
def grid(META):
return (triton.cdiv(q.shape[2], META["BLOCK_M"]), q.shape[0] * q.shape[1], 1)Grid 的 x 维度按 Q 的序列维度分块(每个 block 处理 BLOCK_M 行 Q),y 维度展开 batch 和 head。这意味着:
- 每个 thread block 负责一个 (batch, head, Q_block) 三元组
- 不同 block 之间完全独立,无通信
Q-outer 主循环:_attn_fwd
# fa_tutorial.py L191-L194
start_m = tl.program_id(0) # 当前 block 负责的 Q 行起始位置
off_hz = tl.program_id(1) # batch * head 索引
off_z = off_hz // H # batch 索引
off_h = off_hz % H # head 索引program_id(0) 直接对应 Q 的分块索引 —— 这正是 FA2 “Q 在外层” 的体现。
接着初始化 online softmax 所需的状态变量:
# fa_tutorial.py L216-L218
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf") # 逐行 running max
l_i = tl.zeros([BLOCK_M], dtype=tl.float32) + 1.0 # 逐行 running sum (分母)
acc = tl.zeros([BLOCK_M, HEAD_DIM], dtype=tl.float32) # 输出累加器然后加载 Q tile 到 SRAM,整个内层循环中不再重新加载 Q:
# fa_tutorial.py L222-L223
qk_scale *= 1.44269504 # 1/log(2),用 exp2 代替 exp,避免昂贵的 exp 指令
q = desc_q.load([qo_offset_y, 0]) # Q 只加载一次,常驻 SRAM内层循环:_attn_fwd_inner — 遍历 K/V
# fa_tutorial.py L69
for start_n in tl.range(lo, hi, BLOCK_N, warp_specialize=warp_specialize):每次迭代处理一个 K/V tile。核心计算步骤:
Step 1: 计算 QK^T
# fa_tutorial.py L72-L73
k = desc_k.load([offsetk_y, 0]).T # 加载 K tile 并转置
qk = tl.dot(q, k) # [BLOCK_M, BLOCK_N] = Q @ K^TStep 2: Online Softmax 的 rescale
这是 online softmax 算法的核心。对于非 causal 路径:
# fa_tutorial.py L80-L81
m_ij = tl.maximum(m_i, tl.max(qk, 1) * qk_scale) # 更新 running max
qk = qk * qk_scale - m_ij[:, None] # 减去 max 做数值稳定这里 m_i 是之前所有 K/V tile 的逐行最大值,m_ij 是合并当前 tile 后的新最大值。减去 max 后再做 exp,保证数值稳定性。
Step 3: 计算 attention weights 和修正因子
# fa_tutorial.py L82-L85
p = tl.math.exp2(qk) # P = exp(QK^T / sqrt(d) - max)
alpha = tl.math.exp2(m_i - m_ij) # 修正因子:旧 max 到新 max 的缩放
l_ij = tl.sum(p, 1) # 当前 tile 的 softmax 分母alpha 是关键的 rescale 因子。因为之前累加的 acc 是基于旧的 m_i 计算的,现在 max 更新为 m_ij,所以需要用 alpha 将旧累加结果缩放到新的 scale 上。
Step 4: 更新累加器
# fa_tutorial.py L95
acc = acc * alpha[:, None] # 用修正因子 rescale 旧累加结果
# L101-L103
p = p.to(dtype)
acc = tl.dot(p, v, acc) # 累加当前 tile 的贡献:acc += P @ VStep 5: 更新状态
# fa_tutorial.py L106-L107
l_i = l_i * alpha + l_ij # 更新 softmax 分母
m_i = m_ij # 更新 running max注意 l_i 和 m_i 的更新被放在循环末尾,这是为了减少寄存器压力 —— 让编译器有更多空间调度前面的计算指令。
Causal Mask 的处理:off-band 与 on-band
对于 causal attention,Q 的第 i 行只能 attend 到 K 的前 i 个位置。代码将 K/V 的遍历范围分为两个区域:
# fa_tutorial.py L55-L62
if STAGE == 1: # off-band: Q 行之前的 K(全部合法,无需 mask)
lo, hi = 0, start_m * BLOCK_M
elif STAGE == 2: # on-band: 包含对角线的 K(需要 causal mask)
lo, hi = start_m * BLOCK_M, (start_m + 1) * BLOCK_M
else: # non-causal: 全部 K(无需 mask)
lo, hi = 0, N_CTXoff-band 区域的所有 K 位置都在 Q 行之前,整块都满足 causal 条件,不需要逐元素 mask,直接走快速路径。
on-band 区域包含对角线,块内部分位置需要被 mask 掉:
# fa_tutorial.py L74-L78
if STAGE == 2:
mask = offs_m[:, None] >= (start_n + offs_n[None, :])
qk = qk * qk_scale + tl.where(mask, 0, -1.0e6) # 非法位置加 -inf
m_ij = tl.maximum(m_i, tl.max(qk, 1))
qk -= m_ij[:, None]这种分区域处理是工程上的优化:大多数 tile 走无 mask 的快速路径,只有对角线附近的少量 tile 才做逐元素 mask,最大化计算效率。
Epilogue:最终归一化
# fa_tutorial.py L242-L247
m_i += tl.math.log2(l_i) # 最终 log-sum-exp 值,存下来给 backward 用
acc = acc / l_i[:, None] # 最终除以 softmax 分母
tl.store(m_ptrs, m_i) # 保存 LSE 到 HBM(backward 需要)
desc_o.store([qo_offset_y, 0], acc.to(dtype)) # 写回输出这里额外保存了 m_i + log2(l_i)(即 log-sum-exp 值)到 HBM,这是 backward pass 需要的中间结果。FA2 的 backward 需要 forward 的 LSE 来高效计算梯度。