Flash Attention DeepInsight
我发现每隔一段时间就会忘记 flash attention 具体在做什么。实习一段时间后,对 Attention 的理解也逐渐深入,随之对 FA 算法的理解也更加容易,趁此机会记录一下。
Attention 的本质
我们都知道,Attention 的公式是
但鉴于先前求知欲低下且懒惰,对 Attention 本身对理解甚至也只是两个矩阵乘法和一次softmax而已。要想更好地理解 Flash Attention 这一优雅的工程实现,我们需要先理解 Attention 的本质。
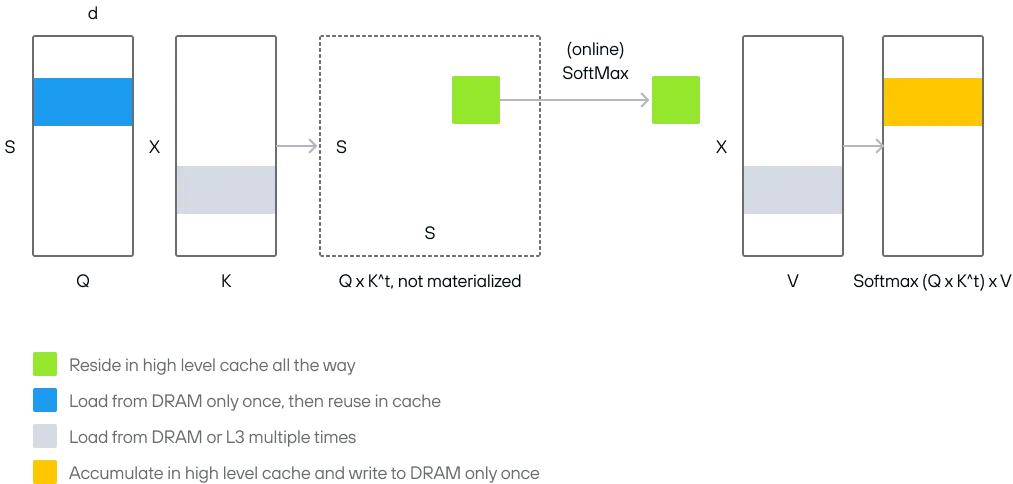
首先我们知道,,其中 分别是序列长度(token 数量)和隐藏维度。公式中的 实际上是在做打分。我们知道,在矩阵乘法 中,结果的第 行第 列 实际上是 的第 行和 的第 列的点积。先不看 softmax,记录 ,那么 其实就是第 个 token 的 query 和第第 个 token 的 key 的点积,这个点积看作 token 对于 token 的得分。那么, 其实就是 token 对其他所有 token 的得分排列而成的向量,过一个 softmax 让它们不至于太大,而得到一个权重 。用这个权重去对所有 token 的 value 进行线性组合,即得到当前 token 的 attention 值。
简而言之,一个 token 的 attention 值,本质上是所有 token 的 value 的线性组合,而线性组合的系数由该token的query与所有token的key点积得到。(暂且不考虑 causal mask)。
Flash Attention 与 GPU 编程的结合
我此前有一些 GPU 编程的基础。对我而言,理解 FA 最大的难点是不知道如何将算法与 CUDA/Triton 的分块对应上。此部分将以结合 Triton 为主。
原始论文中的伪代码想必已经没有人想看了,那么直接来吧。
外层循环:Query、线程块
依旧设 ,我们分块从 query 开始。我们假设把 横向切块, 个 token 的 query 在同一个 block 中,那么 一共会被切成 个块。记第 个块为 (注意不是第 行!)。
其实在上一部份,相信大家也有感觉,第 个 token 的 attention 计算其实就是从其 query 开始的,第 个query最中可以完美对应上 attention 输出的第 行。那么在最简单的 triton 实现中,我们就让第 个 program 来计算第 个块中的 tokens 的 attention 值,也就是从 开始这个 block 的计算。这个 program 其实就对应了 FA 伪代码中最外层的循环。同时,我们记 为这个 block 内的 tokens 对应的输出。
块内循环:KV
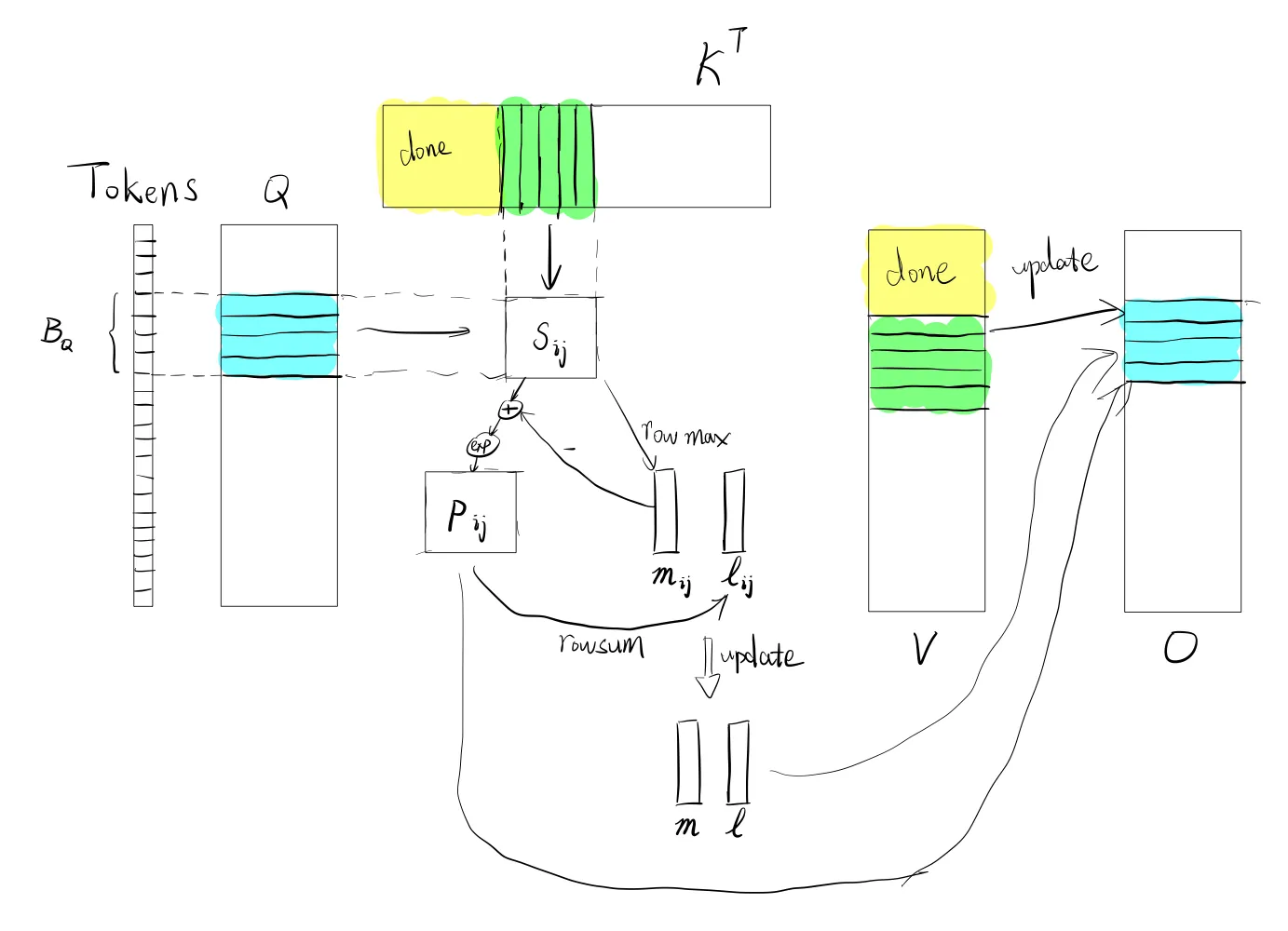
现在,我们进入了 中的 个 token 的 attention 计算。
计算的时候,我们对 K, V 也是要分块的。我们设 K, V 的每个块包含 行,那么它们各会被分成第 个块,记录 为 的第 个块, 同理。计算时,取 K 和 V 的索引值总是一样的。这是因为当一个 query 对 中的几个 token 进行分数计算后,得到的权重对应的 value自然也在 中。
现在,我们就得到了内层循环:对 迭代!
我们先做个记号: 代表
最内层循环,参与计算的分别是 和 。我们可以认为这是一个局部的 Attention,可以计算得到 这部分 token 的局部得分与其 value 的线性组合。从矩阵运算的角度,我们可以看出,这个局部的 Attention 应该是需要累加到 上的。这个累加的方式就是 Flash Attention 的核心:流式 softmax。
简单起见,以下部分不考虑 dropout 和 causal mask。
局部 Attention
首先,进行矩阵乘法,得到初始的局部得分矩阵
然后我们计算两个 softmax 的组件:
- 局部最大得分
- 表示逐行取 max。
- 该组件是为了计算 safe softmax
- 局部指数和
- 表示对 做逐元素指数运算, 表示逐行求和。
- 逐元素减去 是顺应 safe softmax 的需求
这两个操作在 GPU 编程中都可以通过经典的 reduce 算法高效实现,这里不做展开。
流式合并
其实,我们在内层循环中还维护着两个对应的全局组件: 和 ,分别表示当前块之前(前 个 KV 块)的所有 tokens 的得分的最大值。这其实可以看作是两个局部的合并,且与两个局部的大小无关。合并的方法:
- ,这一步很好理解,得到新的最大值
- ,这是因为 和 的每一位在指数上应减去的是新的最大值。原理是乘法分配律和指数乘法,不理解的话可以展开一下。
然后就是最重要的更新输出了: 这里原来的公式做了个提取公因式,我们拆开来看。
- ,其实就是逐行更新原来的 的 safe softmax 的最大值和指数和
- ,即把新块的结果累加上去
对角矩阵是为了逐行操作,这么写是为了数学表达上的简洁。实际上就是用 和 的每一行分别更新每个 token 的输出的分母。
这样,一轮内层循环就完成了。每个线程块其实就是进行内层循环。
以上即是 flash attention 的核心思想。此后会继续更新 flash attention v2、v3、v4 等的实现。